Details of std::mdspan from C++23 -- Bartlomiej Filipek
 In this article, we’ll see details of
In this article, we’ll see details of std::mdspan, a new view type tailored to multidimensional data. We’ll go through type declaration, creation techniques, and options to customize the internal functionality.
Details of
std::mdspanfrom C++23by Bartlomiej Filipek
From the article:
In this article, we’ll see details of
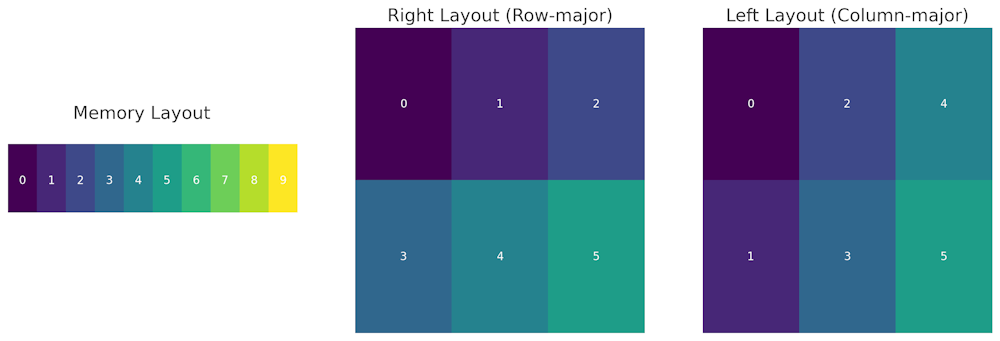
std::mdspan,a new view type tailored to multidimensional data. We’ll go through type declaration, creation techniques, and options to customize the internal functionality.Type declaration
The type is declared in the following way:
template< class T, class Extents, class LayoutPolicy = std::layout_right, class AccessorPolicy = std::default_accessor<T> > class mdspan;And it has its own header
<mdspan>.The main proposal for this feature can be found at https://wg21.link/P0009
Following the pattern from
std::span, we have a few options to createmdspan: with dynamic or static extent.The key difference is that rather than just one dimension, we can specify multiple. The declaration also gives more options in the form of
LayoutPolicyandAccessorPolicy. More on that later.
 Undefined behavior in C++ is a well-known source of headaches for developers, but surprisingly, even the lexing process contained cases of it—until now. Thanks to P2621R3 by Corentin Jabot, unterminated strings, macro-generated universal character names, and spliced UCNs are now formally defined, aligning the standard with real-world compiler behavior.
Undefined behavior in C++ is a well-known source of headaches for developers, but surprisingly, even the lexing process contained cases of it—until now. Thanks to P2621R3 by Corentin Jabot, unterminated strings, macro-generated universal character names, and spliced UCNs are now formally defined, aligning the standard with real-world compiler behavior. A customer attempted to log exceptions using a
A customer attempted to log exceptions using a 
 C++26 will introduce senders/receivers. Lucian Radu Teodorescu demonstrates how to use them to write multithreaded code.
C++26 will introduce senders/receivers. Lucian Radu Teodorescu demonstrates how to use them to write multithreaded code. Contract assertions, introduced in proposal P2900 for C++26, provide a robust mechanism for runtime correctness checks, offering more flexibility and power than the traditional
Contract assertions, introduced in proposal P2900 for C++26, provide a robust mechanism for runtime correctness checks, offering more flexibility and power than the traditional